DFCON: Attention-Driven Supervised Contrastive Learning for Robust Deepfake Detection
Jan 28, 2025·,,,,,,,,,,·
1 min read
MD Sadik Hossain Shanto*
Mahir Labib Dihan*
Souvik Ghosh*
Riad Ahmed Anonto*
Hafijul Hoque Chowdhury*
Abir Muhtasim*
Rakib Ahsan*
MD Tanvir Hassan*
MD Roqunuzzaman Sojib*
Sheikh Azizul Hakim†
M. Saifur Rahman‡
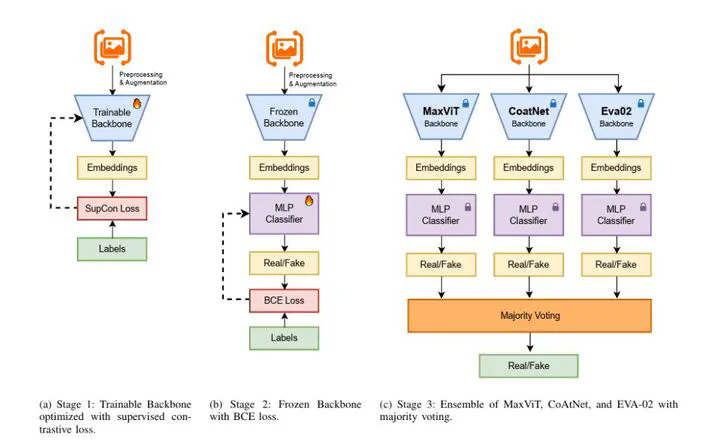 Proposed DFCON framework combining MaxViT, CoAtNet, and EVA-02 with supervised contrastive learning.
Proposed DFCON framework combining MaxViT, CoAtNet, and EVA-02 with supervised contrastive learning.Abstract
This report presents our approach for the IEEE SP Cup 2025: Deepfake Face Detection in the Wild (DFWild-Cup), focusing on detecting deepfakes across diverse datasets. Our methodology employs advanced backbone models, including MaxViT, CoAtNet, and EVA-02, fine-tuned using supervised contrastive loss to enhance feature separation. These models were specifically chosen for their complementary strengths. After training, we freeze their parameters and train classification heads, combining predictions through a majority voting ensemble. The proposed system achieves a commendable accuracy of 95.83% on the validation dataset, demonstrating robustness and generalization across diverse deepfake scenarios.
Type
Publication
arXiv Preprint
This work was developed as part of the IEEE SPS Signal Processing Cup 2025 competition (DFWild-Cup).
We ensemble MaxViT, CoAtNet, and EVA-02 backbones trained with supervised contrastive loss, applying extensive offline and online augmentation for robustness. The final ensemble achieved state-of-the-art accuracy of 95.83% on validation data.
Equal contribution by the first Nine authors.
† Graduate Mentor · ‡ Supervisor
† Graduate Mentor · ‡ Supervisor